The CHIRLA dataset (Comprehensive High-Resolution Identification and Re-identification for Large-scale Analysis) provides a large-scale collection of high-resolution pedestrian images designed to advance research in person identification and re-identification under challenging real-world conditions. It includes diverse viewpoints, lighting variations, and scenes captured with consistent spatial resolution, enabling precise benchmarking of appearance-based recognition methods. The paper introduces the dataset structure, acquisition setup, annotation protocol, and baseline evaluation results, positioning CHIRLA as a robust resource for developing and comparing state-of-the-art algorithms in visual surveillance and computer vision.

The CADDI dataset (In-Class Activity Detection Dataset using IMU data) provides synchronized inertial and visual data for recognizing classroom activities using affordable sensors. It includes recordings from 12 participants performing 19 activities—both continuous (e.g., writing, typing, drawing) and instantaneous (e.g., raising a hand, drinking, turning a page)—captured with a Samsung Galaxy Watch 5 and a ZED stereo camera. The dataset offers over 470 minutes of multimodal data, combining accelerometer, gyroscope, rotation vector, heart rate, and light sensor readings at up to 100 Hz, along with high-resolution stereo images. CADDI serves as a benchmark for developing algorithms to detect and classify in-class human actions, supporting research in educational monitoring and activity recognition

The EMGs Datasets provide two rich collections of sEMG (surface electromyography) data capturing hand gestures. The first set includes recordings from 35 participants (14 female, 21 male) performing 6 distinct gestures across a wide age (16 – 55) and physiological range; the second includes 15 participants (6 female, 9 male) executing 7 gestures (ages 20 – 35). Each dataset is organized in folders, with CSV files storing sEMG signal values (range −128 to 128) per gesture and subject. These datasets support research in gesture recognition using low-cost, non-intrusive sensors.

The UASOL dataset (University of Alicante Stereo Outdoor Dataset) provides over 640,000 high-resolution RGB-D samples captured from a pedestrian’s egocentric perspective on the University of Alicante campus. Each sequence includes stereo image pairs (2208×1242 px, 15 fps), depth maps generated using both Semi-Global Matching and GC-Net, precise GPS localization, and positional tracking. The dataset spans 33 outdoor scenes across varied illumination and weather conditions, featuring sidewalks, roads, vegetation, and human activity. Designed to support depth estimation, stereo reconstruction, and structure-from-motion research, UASOL delivers realistic variability in lighting, motion, and environments, offering a robust benchmark for training and evaluating deep learning models in outdoor vision and 3D perception tasks

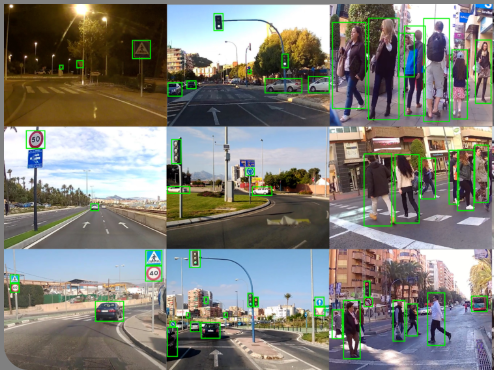
The dataset provides over 200,000 urban driving images and more than 600,000 bounding-box annotations covering key classes such as cars, buses, bicycles, pedestrians, traffic lights and traffic signs — including 43 common European sign types. The authors use this dataset to benchmark a Faster R‑CNN architecture (with VGG16 backbone) and a hybrid detection-tracking scheme, showing how an auto-updated learning strategy (automatically annotated new data) improves detection recall in real-life urban scenarios. This makes the dataset a valuable resource for research in autonomous driving, urban perception and embedded vision systems.
The Large-scale Multiview 3D Hand Pose Dataset provides over 20,500 frames and 82,000 RGB images of human hands captured from four synchronized color cameras, each with detailed 2D and 3D joint annotations, bounding boxes, and segmentation masks. Data were acquired using a custom multi-camera setup combined with a Leap Motion Controller to generate accurate 3D ground truth of 20 hand joints. This resource supports research on 2D/3D hand pose estimation, gesture recognition, and human–computer interaction, and includes a baseline deep learning model for real-time 2D joint estimation

The dataset is a large-scale urban driving object detection benchmark containing over 200,000 images and more than 600,000 bounding-box annotations for seven key classes (car, bus, bicycle, pedestrian, motorbike, traffic light, traffic sign), and additionally 43 different types of traffic signs commonly found in European roads. The images are sourced from existing datasets (such as PASCAL VOC and Udacity) combined with new recordings from vehicle-mounted HD cameras in diverse urban and motorway environments. In addition, a weakly-annotated “auto-updated” subset of video-derived frames is included, enabling research on semi-supervised or weakly supervised learning. This resource supports the development and evaluation of autonomous-driving and embedded-vision systems through baseline performance results obtained with the Faster R‑CNN (VGG16) and YOLOv2 architectures, demonstrating improvements in detection recall when leveraging the auto-update strategy.

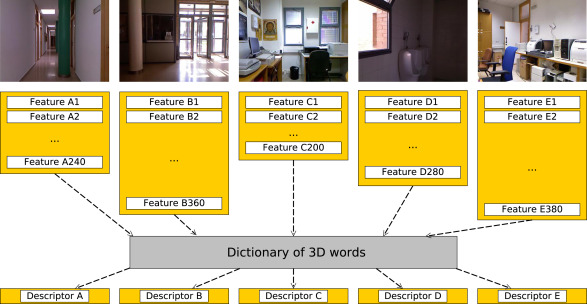
The PCL framework for semantic localization introduces a Bag-of-Words (BoW) implementation within the Point Cloud Library (PCL) to support the creation and evaluation of semantic localization systems using 3D point cloud data. The framework allows the generation of fixed-dimensionality 3D global descriptors from any combination of keypoint detectors and feature extractors, facilitating supervised classification of scenes into semantic categories (e.g., office, corridor). Evaluated on the ViDRILO RGB-D dataset, the study compares multiple 3D detectors (Harris3D, NARF, Uniform Sampling) and descriptors (PFHRGB, Color-SHOT, FPFH), achieving the best performance with the Harris3D + PFHRGB combination (≈ 69 % accuracy). The results demonstrate that the BoW-based framework outperforms traditional global descriptors like ESF while enabling extensibility for future 3D features and machine-learning models
3DCOMET is a dataset for testing 3D data compression methods. we propose a dataset composed of a set of 3D pointclouds with different structure and texture variability to evaluate the results of a compression method. We provide useful tools for comparing compression methods including the results of currently available compression methods in the PCL library as a baseline methods.

ViDRILO is a dataset containing 5 sequences of annotated RGB-D images acquired with a mobile robot in two office buildings under challenging lighting conditions. Each RGB-D image (encoded as .pcd files) is labeled with the semantic category of the scene (corridor, professor office, etc.) but also with the presence/absence of a list of pre-defined objects (bench, computer, extinguisher, etc.). The main novelty of this dataset is the annotation scheme, as well as the large number of annotated RGB-D images. The dataset is released in conjunction with a complete MATLAB toolbox for processing and visualization. This toolbox has been used to assess the dataset in a set of baseline experiments whose results are shown in the experimentation page. ViDRILO is released for use as a benchmark for different problems such as multimodal place classification, object recognition, 3D reconstruction or point cloud data compression.

The proposal for Robot Vision 2014 task is focused on the use of multimodal information (visual and depth images) with application to semantic localization and object recognition. The main objective of this edition is to address the problem of robot localization in parallel to object recognition from a semantic point of view. Both problems are inherently related: the objects present in a scene can help to determine the room category and vice versa. Solutions presented should be as general as possible while specific proposals are not desired. In addition to the use of visual data, depth images acquired from a Microsoft Kinect device will be used, which has demonstrated to be a de facto standard in the use of depth images.
